

یادگیری ماشین یکی از برجستهترین و پرکاربردترین شاخههای هوش مصنوعی است که به سیستمها این امکان را میدهد تا از دادهها یاد بگیرند و بهطور خودکار پیشبینیها و تصمیمات هوشمندانهای بگیرند. یکی از چالشهای کلیدی در این حوزه، نحوه کدگذاری دادهها به شکلی است که الگوریتمهای یادگیری ماشین بتوانند به بهترین نحو عمل کنند.
تعریف کدگذاری دادهها(data encoding)
کدگذاری دادهها به فرایند تبدیل متغیرهای دستهای به نمایشهای عددی اشاره دارد که توسط الگوریتمهای یادگیری ماشین قابل پردازش و درک باشند. الگوریتمهای یادگیری ماشین، بهویژه الگوریتمهای کلاسیک، به طور معمول از مدلهای ریاضی استفاده میکنند که بر مبنای محاسبات عددی و عملیات آماری کار میکنند. این الگوریتمها به دادههایی با فرمت عددی نیاز دارند تا بتوانند الگوها و روابط معناداری را در دادهها شبیهسازی کنند.
دادههای دستهای، مانند برچسبهایی نظیر “قرمز”، “سبز” و “آبی”، بهطور مستقیم توسط الگوریتمها قابل پردازش نیستند. برای حل این مشکل، این دادهها باید به فرمت عددی کدگذاری شوند.
در این مقاله به بررسی تکنیکهای مختلف کدگذاری دادهها خواهیم پرداخت که به الگوریتمهای یادگیری ماشین کمک میکند تا بتوانند بهخوبی از این دادهها استفاده کنند.
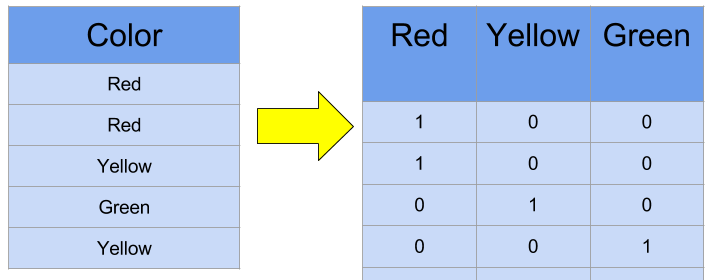
۱. کدگذاری یکبهیک (One-Hot Encoding)
کدگذاری یکبهیک یکی از رایجترین روشها برای تبدیل دادههای دستهای به دادههای عددی است. در این تکنیک، هر دستهبندی به یک بردار باینری تبدیل میشود که در آن تنها یک عنصر مقدار 1 دارد و بقیه مقادیر صفر هستند. این روش معمولاً برای دادههای با تعداد محدود دستهها مناسب است، اما زمانی که تعداد دستهها زیاد شود، ممکن است به ماتریسهای پراکنده و غیرقابلمدیریت منجر شود
۲. کدگذاری ترتیبی (Ordinal Encoding)
کدگذاری ترتیبی برای ویژگیهایی که ترتیب معناداری دارند، مانند مقیاسها یا رتبهبندیها، استفاده میشود. در این روش، هر دسته یک عدد صحیح خاص به خود میگیرد که نشاندهنده رتبه آن در سلسلهمراتب است. به عنوان مثال، در یک رتبهبندی کیفیت محصولات (عالی، متوسط، ضعیف)، میتوان از اعداد 1، 2 و 3 برای نشان دادن هر سطح استفاده کرد.

۳. کدگذاری هدفمحور (Target Encoding)
کدگذاری هدفمحور برای دادههایی با تعداد زیاد دستهها کاربرد دارد. در این تکنیک، هر دسته به میانگین یا مقداری از متغیر هدف (وابسته) کدگذاری میشود. این روش میتواند به کاهش ابعاد دادهها و بهبود عملکرد مدلهای یادگیری ماشین کمک کند. اما باید دقت شود که از مشکل overfitting جلوگیری گردد.

۴. کدگذاری برداری (Embedding Encoding)
در مدلهای پیچیدهتر مانند شبکههای عصبی عمیق، کدگذاری برداری مورد استفاده قرار میگیرد. در این روش، هر دسته به یک بردار با ابعاد کمتر کدگذاری میشود که به مدل این امکان را میدهد که روابط پیچیدهتر بین دستهها را شبیهسازی کند. مدلهای معروفی مانند Word2Vec و GloVe که در پردازش زبان طبیعی استفاده میشوند، از این تکنیک بهره میبرند.
۵. کدگذاری با استفاده از الگوریتمهای یادگیری عمیق (Deep Learning Encoding)
در یادگیری عمیق، کدگذاری دادهها میتواند به طور خودکار توسط شبکههای عصبی انجام شود. این مدلها معمولاً از لایههای مختلف برای استخراج ویژگیهای پیچیده از دادهها استفاده میکنند و میتوانند روابط غیرخطی و پیچیدهتری را شبیهسازی کنند. این تکنیک بهویژه در پردازش دادههای تصویری و متنی کاربرد فراوانی دارد.
نتیجهگیری
انتخاب روش مناسب کدگذاری برای دادهها یکی از عوامل مهم و کلیدی در بهینهسازی عملکرد الگوریتمهای یادگیری ماشین است. تکنیکهای مختلف کدگذاری تأثیر زیادی بر کارایی مدلهای یادگیری ماشین خواهند داشت. انتخاب روش کدگذاری به نوع دادهها، ویژگیهای الگوریتم یادگیری ماشین و هدف نهایی بستگی دارد. بنابراین، آزمایش و ارزیابی روشهای مختلف کدگذاری برای دستیابی به بهترین نتیجه، ضروری است.